

If you have encountered the “Crawled – Currently Not Indexed” message in Google Search Console, it means Google has crawled your page but has not added it to its index, which means it won’t appear in search results. This issue can affect your site’s visibility and organic traffic.
At Search Engine Hub, we have seen this issue many times with our clients, and we have developed effective strategies to fix it. Below, we share practical insights on how to resolve this problem.
What Does “Crawled - Currently Not Indexed” Mean?
When Google crawls your website, its bots visit the pages to gather information. After crawling, Google decides whether to index the page or not. Indexed pages are the ones that appear in search results.
However, if the page is marked as “Crawled – Currently Not Indexed,” it means Google has seen the page but has chosen not to add it to the index for various reasons. This could significantly impact your site’s search rankings.
Common Reasons for “Crawled - Currently Not Indexed”
Several factors could lead to this issue, including:
- Low-quality or thin content where the page lacks sufficient information or value for users.
- Duplicate content when similar content exists elsewhere, making Google avoid indexing.
- Irrelevant content that does not align with search intent or offers little value.
- Technical problems such as noindex tags, robots.txt blocks, or slow loading times.
- Crawl budget limitations where Google prioritizes other pages over yours due to an inefficient crawl budget.
With these potential causes in mind, here’s how you can go about fixing the issue.
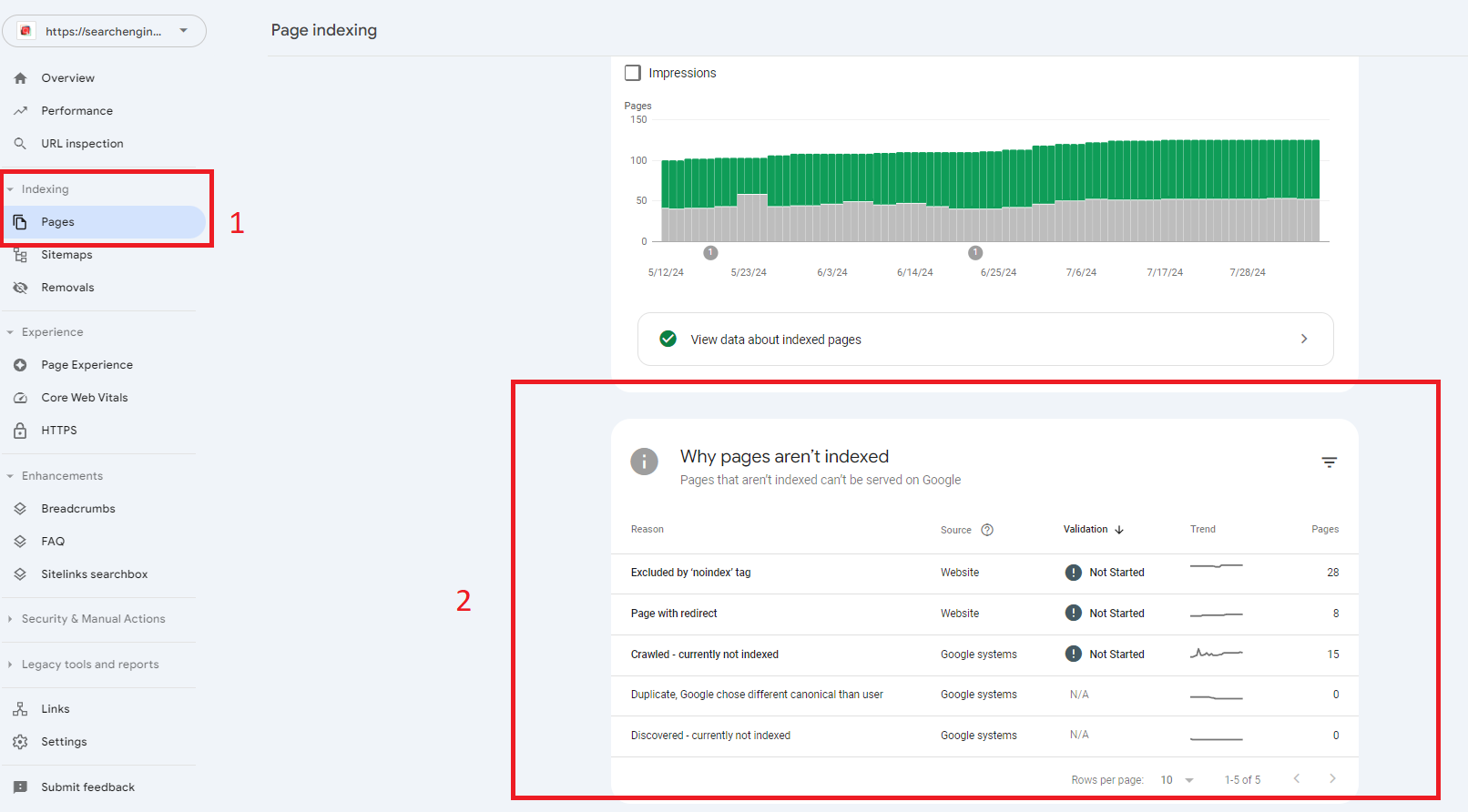
Step 1: Identify Pages Affected by the Issue
The first thing to do is find out which pages are affected by this problem.
- Open Google Search Console and access your website’s dashboard.
- Navigate to the “Pages” Report, under the “Indexing” section, click on “Pages.” This report provides a breakdown of which pages are indexed and which are not.
- Check the “Why Pages Aren’t Indexed” Tab, in this section, look for URLs listed under the “Crawled – Currently Not Indexed” label. These are the pages Google has crawled but decided not to index.
Once you have a list of affected URLs, you can move forward with resolving the issue.
Step 2: Evaluate and Improve Content Quality
Content quality plays a major role in whether Google indexes your page. From our experience with clients, we have found that improving content quality is often the first step in getting pages indexed. Google prefers to index pages that provide value to users. To improve your chances of indexing, follow these steps:
- Check for thin content that does not provide enough valuable information. Pages with minimal content are less likely to be indexed. Make sure your content is comprehensive, answers user queries, and meets the search intent.
- Add more relevant content, images, or videos where necessary.
- Ensure the information on your page is detailed and specific to your audience’s needs.
- Avoid duplicate content by ensuring your page offers unique information. If your page is similar to others on your site or elsewhere, Google may skip indexing it. Combine or rework similar content to ensure it is unique.
- Enhance readability and engagement by using headings, bullet points, and short paragraphs to make the content easier to digest. Adding internal links to related pages can also improve engagement.
Improving the quality of your content is crucial for improving its chances of being indexed.
Step 3: Fix Technical Issues Blocking Indexing
Technical factors can also prevent Google from indexing your page, even if the content is high quality. Common technical problems include incorrect noindex tags, robots.txt issues, or poor page performance. Here’s what you should look out for:
- Noindex tags are instructions that tell Google not to index a page. Check your page’s HTML or use a tool like Screaming Frog to see if any noindex tags have been mistakenly applied. Remove these if necessary.
- Robots.txt files can block Google from crawling certain sections of your site. Make sure your robots.txt file is not accidentally blocking the affected pages from being crawled.
- Making sure your site is optimized for mobile is essential, as Google uses mobile-first indexing. Ensure that your page is responsive and functions well across all devices, focusing on user experience, such as readability, navigation, and loading speed on mobile devices.
- Page loading speed can also affect indexing. Slow pages may not be prioritized by Google. Use Google PageSpeed Insights to identify and fix performance issues such as large images or excessive JavaScript.
- Fix broken links that might prevent Google from properly crawling your page. Tools like Ahrefs or Screaming Frog can help you locate and resolve broken links or errors.
Addressing these technical issues removes barriers that might be preventing your page from being indexed.
Step 4: Strengthen Internal Linking
Google relies heavily on internal links to discover and index your pages. If your affected pages are poorly linked within your site, Google may miss them during the crawling process. To improve your internal linking strategy, focus on the following:
- Add links from high-authority pages that are already performing well. Linking from these pages to the affected ones can pass authority and help Google find and index them.
- Ensure a clear site structure by organizing your internal links logically. Use a hub-and-spoke model, where your main pages link out to relevant sub-pages, making it easier for Google to crawl and index.
We’ve seen this strategy improve the indexing rate for many of our clients’ sites.
Step 5: Submit Pages for Indexing in Google Search Console
Once you have improved your content and fixed any technical issues, it’s time to request indexing through Google Search Console. You can manually submit pages for re-indexing, and here’s how:
- Open the URL Inspection Tool in Google Search Console.
- Enter the URL of the page you want Google to index.
- Click “Request Indexing” to submit the page for crawling again.
Keep in mind that it might take some time for Google to process your request and index the page. Regularly check back in Search Console to monitor the status.
Step 6: Optimize Your Crawl Budget
Your crawl budget determines how many pages Google will crawl and how frequently. If Google is using its budget to crawl unimportant or low-value pages, it may ignore the more critical pages, leaving them unindexed.
- Remove low-value or redundant pages that do not contribute to your website’s overall quality. This includes outdated or irrelevant content that may dilute your crawl budget.
- Ensure that canonical tags are correctly used to avoid duplicate content issues and help Google understand which version of a page to prioritize.
- Regularly update your sitemap, keeping only the essential and relevant pages that you want Google to crawl and index. This allows Google to focus on the most important content.
Step 7: Monitor Your Progress
After completing all the steps above, monitoring your progress is essential. Here’s what you should do:
- Regularly check Google Search Console’s Pages report under the “Indexing” section to monitor the status of affected pages.
- Continuously update your content, resolve technical issues, and optimize your crawl budget to improve indexing results.
- Keep an eye on any changes or new issues in the Pages report to ensure your website remains indexed properly.
Our Final Thoughts
Fixing the “Crawled – Currently Not Indexed” issue is critical to improving your website’s visibility and performance in search results. Through our experience with SEO clients, we have found that improving content quality, fixing technical issues, strengthening internal linking, and optimizing the crawl budget are essential steps to resolving this issue.
Regular monitoring of your site using Google Search Console ensures that any new problems are identified and fixed quickly, helping maintain a strong SEO performance over time.
If you’re looking for ongoing support, our monthly SEO plan can help ensure your site stays optimized, fully indexed, and continues to perform well in search engines. Get in touch with us to learn more about how we can assist with all your SEO needs, including resolving indexing issues and boosting your site’s rankings.



